.gif)







۱.فضای حالت (State Space): بازتابی دقیق از درک محیط و دینامیک ربات
یکی از الزامات اساسی برای موفقیت یک مدل یادگیری تقویتی در کنترل ربات، تعریف دقیق و هدفمند فضای حالت است. این فضا، معرف «دانش لحظهای» عامل از جهان پیرامون خود است؛ یعنی هر آنچه که باید بداند تا بتواند تصمیم درستی بگیرد. در مدل ارائهشده در مقاله، فضای حالت بهگونهای طراحی شده که هم اطلاعات دینامیکی ربات را شامل شود، هم بازنمایی دقیقی از محیط متغیر را در خود داشته باشد.
در این محیط، عامل یک بازوی ۷ درجه آزادی است که در یک فضای کاری سهبعدی، باید به نقطه هدف برسد و همزمان از برخورد با موانع متحرک جلوگیری کند. بنابراین، فضای حالت شامل مؤلفههایی از چند دسته زیر است:
مشخصات سینماتیکی–دینامیکی بازو: زاویه مفصلها، سرعتهای مفصلی، گشتاورهای فعلی، وضعیت اندافکتور (موقعیت و سرعت خطی و زاویهای)، که همگی از طریق سیستم کنترل پاییندست قابل مشاهده هستند.
اطلاعات موقعیتی هدف: بردار موقعیت و وضعیت هدف نسبت به اندافکتور، که جهتدهی کلی حرکت را تعریف میکند.
موقعیت و سرعت موانع متحرک: که بهصورت بردارهای نسبی بیان میشود. بهجای ثبت مطلق موقعیت موانع، فاصلهی آنها تا اندافکتور و جهت حرکت نسبیشان استفاده میشود تا مدل بهتر بتواند ریسک برخورد را پیشبینی کند.
مقادیر ایمنی مجاورتی: مانند فاصله تا نزدیکترین مانع، نرخ تغییر فاصله، و سایر پارامترهای مرتبط با تماس (Contact Margin) که در تنظیم رفتار اجتنابی مؤثر هستند.
این ترکیب اطلاعات باعث میشود عامل در هر لحظه «ادراکی ترکیبی» از موقعیت خود، هدف، و محیط پیرامون داشته باشد — مشابه چیزی که یک انسان کنترلگر باتجربه در محیط واقعی حس میکند. نتیجه این طراحی، افزایش تعمیمپذیری و کاهش رفتارهای وابسته به جزئیات خاص محیط است.
۲. فضای عمل (Action Space): طراحی کنترلی در سطح گشتاور پیوسته برای پاسخ نرم و دقیق
انتخاب فضای عمل، مستقیماً تعیین میکند که خروجی شبکه عصبی یادگیرنده به چه صورت فرمان صادر کند. در مدل پیشنهادی مقاله، فضای عمل بهصورت پیوسته و بر پایه گشتاور اعمالی به مفصلها تعریف شده است. این انتخاب به چند دلیل کاملاً مهندسیشده و متناسب با سیستمهای واقعی کنترل بازوهای رباتیک است.
اولاً، در بیشتر بازوهای صنعتی سطح بالا، کنترل در سطح گشتاور، امکان مانورهای دقیقتر و سازگاری بهتر با محدودیتهای فیزیکی را فراهم میکند. برخلاف کنترل موقعیتی یا سرعتی که با تأخیر و overshoot همراهاند، گشتاور بهطور مستقیم بر دینامیک تأثیر میگذارد.
دوماً، فضای عمل پیوسته باعث میشود عامل بتواند خروجیهای بسیار نرم، بدون پرش و با دقت بالا تولید کند. این موضوع بهویژه در مواجهه با موانع متحرک ضروری است، چون کوچکترین پرش یا تغییر ناگهانی در فرمان میتواند منجر به برخورد یا بیثباتی شود.
در پیادهسازی مقاله، خروجی شبکه Actor شامل ۷ مقدار پیوسته (برای ۷ مفصل) است، که هر یک از یک توزیع گوسین یادگرفتهشده نمونهبرداری میشوند و با تابع tanh محدود میگردند تا در بازههای فیزیکی مجاز قرار گیرند. این ساختار اجازه میدهد ربات: در حین اجرای مانور، از منابع مکانیکی فراتر نرود، اعمالی مطابق با محدودیتهای صنعتی (torque, slew rate) صادر کند و از رفتارهای نوسانی، لرزشی یا غیرایمن پرهیز کند نتیجه آن یک سیاست کنترلی دقیق، روان و با قابلیت پیادهسازی مستقیم روی سیستم کنترل سطح پایین است.
۳. تابع پاداش: معماری چندبخشی برای توازن بین دقت، ایمنی و پایداری حرکتی
تابع پاداش در یادگیری تقویتی، اصلیترین عامل شکلگیری سیاست یادگیرنده است. طراحی نادرست آن میتواند باعث یادگیری رفتارهای غیربهینه، پرخطر یا ناپایدار شود. در این مقاله، نویسندگان یک تابع پاداش مرکب تعریف کردهاند که چند هدف حیاتی را بهطور همزمان به عامل منتقل میکند. ساختار این تابع شامل مؤلفههای زیر است:
پاداش هدفگرا: کاهش فاصله بین اندافکتور و هدف در هر گام زمانی پاداش مثبت دارد. اگر فاصله افزایش یابد، پنالتی اعمال میشود. این بخش، عامل را بهسوی هدف هدایت میکند.
پنالتی برخورد: برخورد فیزیکی با موانع یا عبور از حداقل فاصله مجاز، جریمه سنگینی دارد. این مؤلفه ایمنی حرکت را تضمین میکند.
پنالتی مانور شدید: اعمال گشتاورهای بسیار بزرگ یا تغییرات ناگهانی در عمل، پنالتی دارد تا رفتار کنترل نرمتر شود.
پاداش تکمیل موفق مأموریت: در صورت رسیدن به هدف بدون برخورد در طول اپیزود، پاداش نهایی قابل توجهی در نظر گرفته شده تا سیاست به سمت دستیابی ایمن سوق یابد.
این طراحی باعث میشود که عامل هم یاد بگیرد چگونه سریع و دقیق حرکت کند، هم چگونه ایمن و پایدار باقی بماند. بهبیان دیگر، عامل نهفقط بر پایه رسیدن، بلکه بر پایه کیفیت رسیدن نیز پاداش دریافت میکند — و این چیزی است که در محیطهای صنعتی حیاتی است.
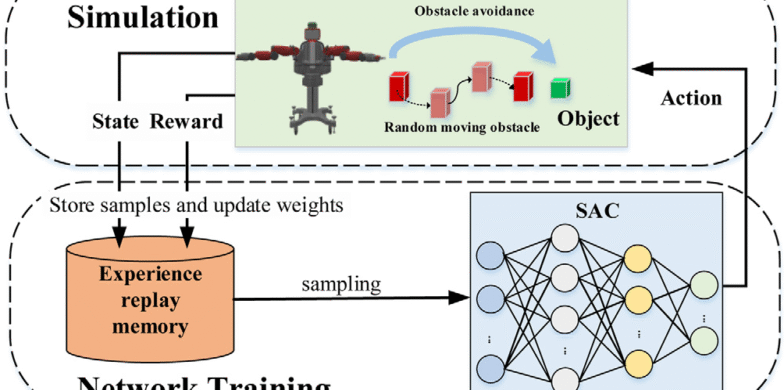
۴. فرآیند آموزش: یادگیری ایمن و تعمیمپذیر از تجربههای هدفمند
آموزش مدل در این مقاله، در یک محیط شبیهسازیشده انجام شده که شامل سناریوهای متعدد با وضعیتهای اولیه و موقعیت موانع متغیر است. هر اپیزود با یک مقداردهی اولیه تصادفی آغاز میشود تا مدل رفتار تعمیمیافته بیاموزد. مراحل کلیدی فرآیند آموزش:
Replay Buffer اولویتدار (PER): تجربیاتی که دارای خطای بالا، برخورد یا تغییر شدید در مقدار Q هستند، با احتمال بالاتری مجدداً بازپخش میشوند. این باعث تسریع یادگیری و افزایش تمرکز روی دادههای بحرانی میشود.
Dual Critic Networks: برای کاهش overestimation، دو شبکه Q مستقل آموزش داده میشوند و مقدار کمتر از آنها استفاده میشود.
Target Networks و Soft Update: برای پایداری بیشتر، شبکههای هدف با نرخ آهسته بروزرسانی میشوند تا نوسان آموزش کاهش یابد.
Exploration تصادفی با آنتروپی: عامل از توزیع گوسین با واریانس کنترلشده نمونهبرداری میکند تا رفتارهای اکتشافی ایمن ایجاد شود.
معماری بازیابی خطا (Recovery): اپیزودها در شرایطی که عامل رفتار بسیار ناایمن نشان دهد (مثلاً برخورد سخت)، زودتر خاتمه مییابند تا از یادگیری مسیرهای اشتباه جلوگیری شود.
این فرایند، با ساختار شبکه سبک و قابل اجرا روی سختافزارهای تعبیهشده، نهتنها کارآمد، بلکه آماده برای انتقال به سیستمهای رباتیک واقعی در شرایط بلادرنگ است.




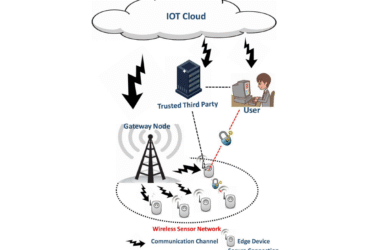


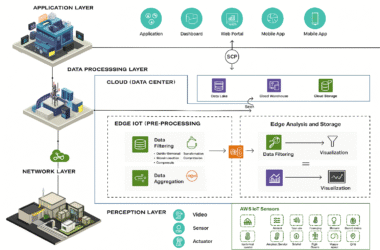
دیدگاهتان را بنویسید